Figures
Figure 1 � Copycat Slipnet
see attached file � �copycat slipnet organisation.pdf�
Figure 2 � Copycat Workspace for the abc/xyz problem
Greg Detre
Harvard University, Cambridge, MA
email: grog@dial.pipex.com
The perception of an event or object must include the simultaneous computation of several different descriptions of it, that capture diverse aspects of the use, purpose or circumstances of the event or object � [Marr, 1977, pg 44]
This paper briefly describes the main debate within the computational analogy-making community, then describes the architecture of Copycat, one of the most famous computational models of analogy-making.
The main debate in the computational analogy-making literature is best characterised by a comparison between the �Structure Mapping Theory� and �Higher Level Perception� camps [French, 2002].
According to SMT, an analogy is an �alignment of relational structure� [Gentner & Markman, 1997]. Here, the relations are the internal links that determine the composition and arrangement of the structure, which are contrasted with the �attributes� and �object descriptions� which determine �mere-appearance matches�. Morrison & Dietrich [1995] consider that Gentner et al.�s aim is to present a model of the comprehension (rather than the discovery) of analogy, where for a given structure, the system is able to retrieve a stored match for which the mapping of relations is closest. Their implementation, SME,� starts by seeing many local matches out of which a consistent large-scale structure coalesces, and appears to mirror certain salient experimental results with human subjects.
In contrast, Hofstadter and the FARG [Hofstadter, 1995] want to cast analogy-making as playing a much more central and less specialised role � �analogy-making is going on constantly in the background of the mind, helping to shape our perceptions of everyday situations. In our view, analogy is not separate from perception: analogy-making itself is a perceptual process� [Chalmers, French and Hofstadter, 1991].
This needs a little explaining. The central point is that the process of building up a compound representation of a situation or scenario cannot be independent of the process of seeing a mapping between scenarios. Both of these processes are intertwined as �high-level perception�. High-level perception begins at that level of processing where concepts begin to play an important role. This is pretty nebulous, but that�s fine. We can see concepts as being abstract or concrete, simple or complex � any aggregation, processing or filtering of raw sensory data can be seen as conceptualising.
The two problems in high-level perception are the problems of relevance and of organisation:
1. relevance � how do you determine what�s salient within the morass of low-level data, and pick it out to pass on to higher levels of processing?
2. organisation � how do you organise all of that (multi-modal) data together, i.e. how do you determine what to clump together and what�s related to what?
These two problems are critical for SMT, since if the wrong
aspects of the perceptual data are chosen, or if they are organised poorly, no
analogies will ever be found. Yet this is out of SME�s control, because it
artificially separates the processes of human hand-coding of perception and its
own mapping. The same criticism Hofstadter made of Bacon [Langley et al., 1987]
could be made of SME, namely that it �was fed precisely the data required to
derive the [Kepler�s] law� [Hofstadter, 1995].
In other words, analogy-making requires representations to be built dynamically, extracting, organising and reorganising what�s salient about the current situation based on the current context, goals, beliefs, and at the same time as trying to perform tentative mappings with past situations and knowledge. To comprehend an analogy is to discover it � you can�t do the former in any rich, flexible or meaningful way without doing the latter.
Copycat is intended to illustrate how the various strata of such a view of analogy-making as high-level perception could operate and interact, involving:
� the gradual building-up of representations
� the role of top-down and contextual influences
� the integration of perception and mapping
� the exploration of many possible paths towards a representation
� the radical restructuring of perceptions, when necessary
Copycat considers analogies like the following:
abc
�:�
abd� ::� ijkk �:� ?
Most people would prefer ijll, but would recognise the validity of ijkl, ijkd, ijdd or abd, to name just a few. Copycat�s architecture is designed to allow top-down and bottom-up influences to interact, constraining a search[1] through the space of possible mappings between letter-strings, and so producing a mapping to a new string, as well as providing a rating of the system's �happiness� with its solution. This could be seen in three main (concurrent) tasks:
1. build a representations of the three starting strings
2. describe how to map from the source to target strings
3. apply the same transformation to the third string
There are a number of things about the Copycat architecture that are special or interesting. It�s split into three parts:
This is the high-level, long-term conceptual memory of Copycat (see Fig. 1), represented as a semantic network. It contains concepts like �successorship�, �rightmost�, �opposition� and �symmetry�, each of which are linked together by proximity (i.e. association) weights. Each concept has a pre-assigned �conceptual depth� and activation. The conceptual depth is a sort of aesthetic, subjective, hand-coded value intended to capture how abstract or interesting a concept is. The activation reflects the extent to which the concept appears to be relevant to the current problem, and how activated nearby/associated concepts are.
Coderack
The Coderack is the repository for the codelets � these are small, specific pieces of code that carry out low-level tasks. Some codelets look for particular patterns, or evidence that a given concept may be playing a role somewhere, while others build bonds and groups within a string, or bridges/correspondences between strings, and finally some break these structures back down again when Copycat seems to be hitting an impasse.
Each codelet is selected probabilistically from the Coderack according to its �urgency�, which is partly hand-coded, and partly a function of the current activations and deformations in the Slipnet, and partly affected by the preceding codelets which triggered it.
Workspace
This is a sort of scratchpad on which the codelets operate, containing the strings, and the structures built up between them. The strength of a structure is a function of the activation and conceptual depth of the related concept (e.g. sameness, successorship), how long it has lasted, whether it conflicts with other structures, amongst other factors. Structures can be nested. I find it useful to think of the Workspace structures as tokens of Slipnet concept-types.
Copycat is great at interacting top-down and bottom-up, being mostly sensible but not myopically systematic, and building structures so that they �flex� in the right places. Hofstadter terms the system�s overall approach a parallel terraced scan, which can be understood in search terms as exploring the most promising avenues proportionally/probabilistically more. Where the agenda of a depth-first search is a stack, and breadth-first uses a queue to decide the next node, the parallel terraced scan uses a stochastic priority-queue of codelets, ordered by their �urgency�. These priorities are based on the bi-directional interactions between the top-down associations and concept activity-values in the Slipnet and the happiness and salience of the bottom-up structures built by the codelets.
Finally, the temperature is a measure of the richness and internal coherence of the structures that have been built up so far in the Workspace. When these structures are weak, employing conceptually shallow concepts, and when large parts of the strings haven�t been accounted for or don�t fit, the temperature is high, making all the processes more stochastic, and increasing the urgency of dismantler codelets. As the system builds more coherent structures, the temperature drops, and the decisions become more deterministic and less destructive. The temperature can then be seen as a kind of measure of the system�s happiness with the solution it has found. As a result, Copycat may find a less satisfying analogy quite often (it has no memory of past solutions), but occasionally stumble across a highly satisfying solution, mirroring results with human experimental subjects.
An example should suffice to convey the difference between more common and more satisfying solutions. If faced with the problem:
abc
�:�
abd� ::� xyz �:� ?
most people�s first choice would probably be xya, since we want to find a successor to the rightmost letter and so we loop back through the alphabet. However, a circular link from �z� to �a� has been deliberately excluded from Copycat�s conceptual model, which forces people to think harder.
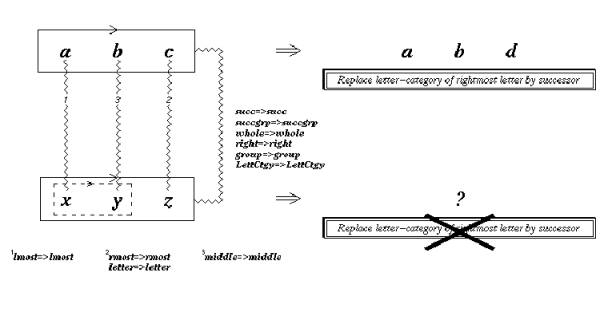
As a result, Copycat frequently builds up a set of structures on the Workspace that lead it to seek the successor of the rightmost letter, only to hit an �impasse� (see Fig. 2). This happens often because Copycat�s parameters are set so that it sees successorship groups more readily than predecessorship groups, which is intended to reflect human (especially Western) preferences for incrementing over decrementing and left-to-right over right-to-left.
As a result, the solutions it comes up most commonly include xyz, xyy, xyd and abd. However, there is a solution that many people find very satisfying once they see it, though few people notice it immediately, which is wyz. This requires a mini paradigm shift. The impasse occurs because abc is described as a group of successors heading rightwards from the first letter of the alphabet, and the most obvious mapping is to see xyz correspondingly as a group of successors heading rightwards ending on the last letter of the alphabet. In order to scale the impasse, xyz has to be reconceptualised as a group of predecessors heading leftwards from the last letter of the alphabet. This is exactly symmetrical to the description of abc, prompting a reversal of the rule from abc to abd of �replace the rightmost letter with its successor� to �replace the leftmost letter with its predecessor�. When I first saw this, I certainly felt that the choice of the seemingly uninteresting letterstrings microdomain as allowing for complex, psychologically plausible constructions was vindicated. Copycat finds the less satisfying solutions more often, but when it does find the wyz solution its satisfaction with the solution (as measured by a lower temperature) is much higher [See Hofstadter, 1995; and Mitchell, 1993 for a plethora of further letterstring puzzles that Copycat can solve].
see attached file � �copycat slipnet organisation.pdf�
[1] Although Hofstadter avoids the word �search� in the context of thinking because of the connotations of formal, efficient techniques for searching well-defined spaces, that he rejects [Kelly, 1995].